Normality is one of the most important assumptions in statistical analysis. Before running t-tests, ANOVA, regression, or any parametric test, you need to know whether your data follows a normal distribution. If it doesn’t, your results may be misleading – and any insights drawn from them, unreliable.
SPSS makes normality testing straightforward, but only if you know which tests to run, how to read the output, and what to do when your data fails the assumption.
This guide walks you through every step: the menu path, the tests to use, how to interpret the numbers, and how to handle non-normal data. It is written for researchers, analysts, and market research teams who need clean, defensible results to support faster decision-making.
Why Normality Testing Matters
Most parametric tests assume that your continuous variable is approximately normally distributed. When this assumption holds, your test results are accurate, and your conclusions are sound. When it fails, you risk:
- Inflated Type I or Type II errors
- Misleading confidence intervals
- Incorrect p-values
- Flawed business or research decisions
For organisations running large-scale studies, normality testing is not a checkbox. It is a quality gate. It protects the integrity of every analysis that follows and ensures the data feeding into reports, dashboards, and stakeholder presentations is fit for purpose.
In market research, where insights guide product launches, pricing strategy, and customer experience investments, getting this step right is non-negotiable.
What “Normal Distribution” Actually Means
A normal distribution is symmetrical and bell-shaped. The mean, median, and mode are roughly equal. Most values cluster around the centre, with fewer values appearing as you move toward the extremes.
In real-world datasets, perfect normality is rare. What you are testing for is whether your data is approximately normal – close enough that parametric tests will produce reliable results.
There are two ways to assess this in SPSS:
- Numerical methods – statistical tests that give you a clear yes or no
- Graphical methods – visual plots that show the shape of your data
Best practice is to use both. Numbers give you objectivity. Plots give you context.
Methods SPSS Provides for Testing Normality
SPSS offers several tools for normality assessment, all accessible through the Explore command:
| Method | Type | Best For |
| Shapiro-Wilk Test | Numerical | Sample sizes under 2,000 (most reliable for n < 50) |
| Kolmogorov-Smirnov Test | Numerical | Larger samples, less sensitive than Shapiro-Wilk |
| Skewness & Kurtosis | Numerical | Quick descriptive check |
| Histogram | Graphical | Visual shape assessment |
| Normal Q-Q Plot | Graphical | Comparing data to a theoretical normal distribution |
| Box Plot | Graphical | Spotting outliers and symmetry |
The Shapiro-Wilk test is the most widely recommended numerical test. It is sensitive and works well across most sample sizes you will encounter in research projects.
Step-by-Step: Testing Normality in SPSS
Here is the full procedure using the Explore command. This works in SPSS versions 17 through 30, including the subscription version.
Step 1: Open the Explore Dialogue
From the top menu, click: Analyze → Descriptive Statistics → Explore…
This opens the Explore dialogue box.
Step 2: Move Your Variable into the Dependent List
Select the continuous variable you want to test for normality. Move it into the Dependent List box using the arrow button or drag-and-drop.
If you want to test normality across groups – for example, comparing male and female respondents – move your categorical grouping variable into the Factor List box. SPSS will then test normality for each group separately.
Step 3: Configure the Plots
Click the Plots… button. In the dialogue that opens:
- Tick Histogram
- Keep Stem-and-leaf ticked
- Tick Normality plots with tests
This single setting unlocks the Shapiro-Wilk and Kolmogorov-Smirnov tests along with the Q-Q plot.
Step 4: Run the Analysis
Click Continue, then click OK in the main Explore dialogue.
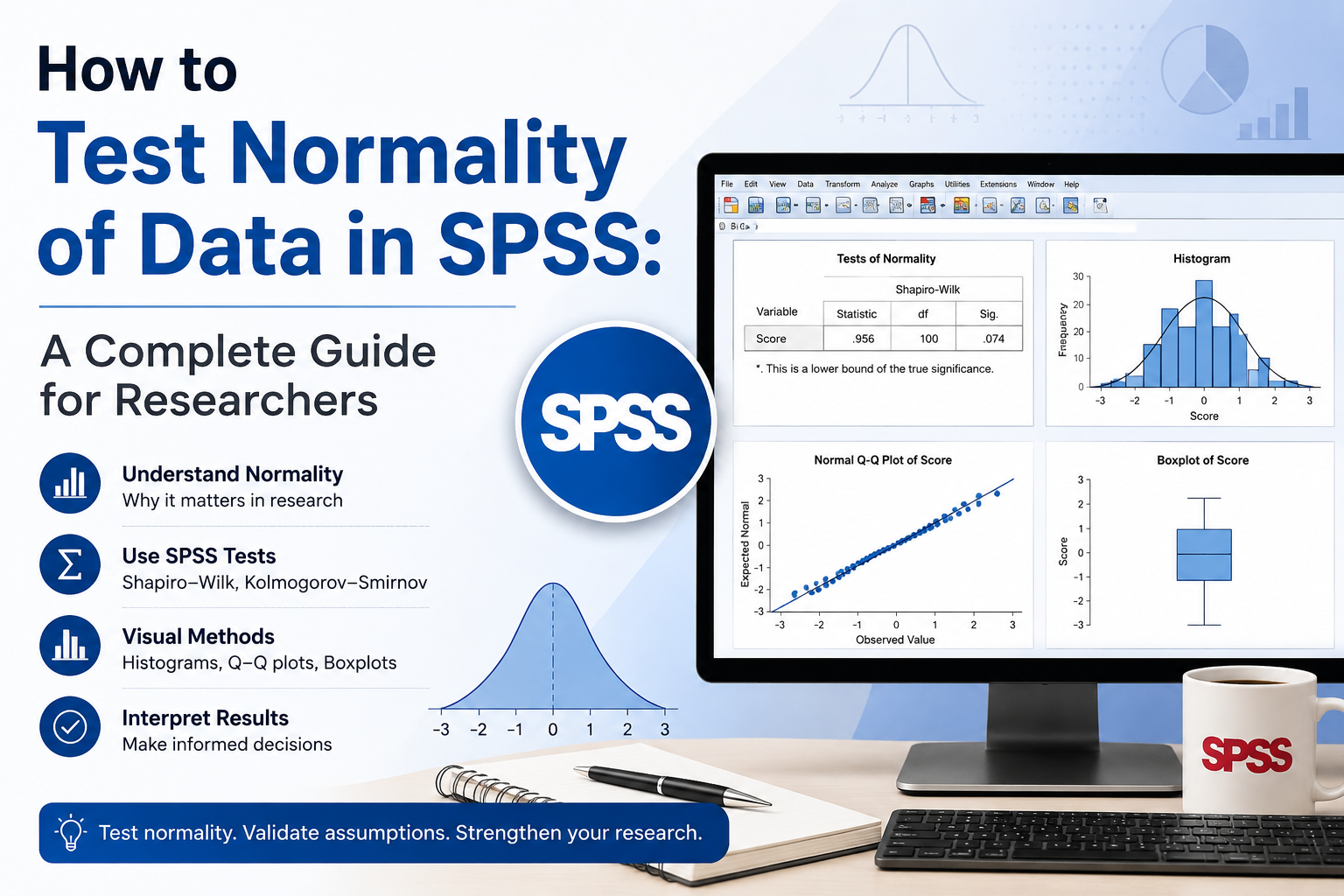
SPSS will generate a full output including descriptive statistics, the Tests of Normality table, histograms, stem-and-leaf plots, Q-Q plots, detrended Q-Q plots, and box plots.
Reading the SPSS Output
The output looks dense at first. Focus on these key sections.
The Tests of Normality Table
This is the heart of your numerical assessment. Look at the Sig. (p-value) column under Shapiro-Wilk.
- p > 0.05 → Data does not significantly deviate from normality. Assumption is met.
- p < 0.05 → Data significantly deviates from normality. Assumption is violated.
Note the logic carefully. A high p-value is good news. It means there is no significant difference between your data and a normal distribution.
Skewness and Kurtosis
In the Descriptives table, check the skewness and kurtosis values.
- Skewness measures asymmetry. Acceptable range: -1 to +1.
- Kurtosis measures the peakedness of the distribution. Acceptable range: -1 to +1.
You can also calculate z-scores by dividing each value by its standard error. Z-scores between -1.96 and +1.96 indicate acceptable normality at the 0.05 level.
Histogram
Look for a roughly symmetrical, bell-shaped curve. Double-click the histogram in SPSS to open the Chart Editor, then add a distribution curve to make symmetry easier to judge.
Normal Q-Q Plot
In a Q-Q plot, your data points are compared to a theoretical normal distribution. If the points lie close to the diagonal line, your data is approximately normal. Significant departures from the line – curves, S-shapes, or scattered points – suggest non-normality.
Box Plot
A symmetrical box, whiskers of similar length, and no outliers suggest normality. Heavy tails or visible outliers may indicate problems.
A Worked Example
Imagine a market research dataset measuring customer satisfaction scores for 80 respondents in a brand-tracking study. You run the Explore procedure and get the following:
- Mean: 22.01
- Median: 22.00
- Skewness: 0.049 (well within -1 to +1)
- Kurtosis: -0.442 (within -1 to +1)
- Shapiro-Wilk p-value: 0.585
The histogram is roughly symmetrical. Points on the Q-Q plot sit close to the diagonal line. The box plot is symmetric with no outliers.
Conclusion: The variable is approximately normally distributed. You can proceed with parametric tests.
This is the kind of clean, defensible result every research team wants. When all indicators agree, the decision is clear. When they disagree, you need to make a judgment call.
What to Do When Indicators Disagree
Sometimes the Shapiro-Wilk test says one thing and the histogram suggests another. This is common with large samples. The Shapiro-Wilk test becomes very sensitive at high n – it can flag trivial deviations as statistically significant.
Use this decision framework:
- Small sample (n < 50): Rely more heavily on the Shapiro-Wilk test.
- Medium sample (50–300): Combine Shapiro-Wilk with skewness, kurtosis, and visual plots.
- Large sample (n > 300): Trust visual methods more. The Central Limit Theorem also means many parametric tests are robust to mild non-normality at this scale.
For high-stakes research, document your reasoning. State which methods you used, what they showed, and why you made the call you did. This transparency strengthens the credibility of your findings.
Testing Normality Across Groups
In many studies, you need normality within each group of a categorical variable – not just the overall sample. For example, testing whether income is normally distributed for both urban and rural respondents before running a t-test.
The procedure is the same:
- Analyze → Descriptive Statistics → Explore…
- Move your continuous variable into the Dependent List
- Move your grouping variable into the Factor List
- Configure plots as before
- Click OK
SPSS will produce separate statistics and graphs for each group. You may find that data is normal in one group and not the other. This is important information for choosing your next test.
What If Your Data Fails the Normality Test?
A failed normality test is not the end of your analysis. You have several options.
1. Transform the Variable
Common transformations include:
- Logarithmic transformation for right-skewed data
- Square root transformation for moderately skewed data
- Inverse transformation for severely skewed data
- Reflect-and-transform for left-skewed data
In SPSS, use Transform → Compute Variable… to create a new variable. Then retest the transformed variable for normality.
2. Use Non-Parametric Tests
If transformation does not help, switch to a non-parametric equivalent:
- Mann-Whitney U instead of an independent samples t-test
- Wilcoxon signed-rank instead of a paired t-test
- Kruskal-Wallis instead of one-way ANOVA
- Spearman’s correlation instead of Pearson’s
Non-parametric tests do not assume normality. They are less powerful but more robust.
3. Rely on the Central Limit Theorem
For large samples, parametric tests are remarkably robust to non-normality. If n is large enough – typically over 30 per group, often more – mild violations of normality may not meaningfully affect your results.
4. Investigate Outliers
Sometimes non-normality is caused by a handful of extreme values. Examine your data for entry errors, measurement issues, or genuine anomalies. Removing or correcting outliers – with proper justification – can restore normality.
Common Mistakes to Avoid
Even experienced analysts slip up here. Watch for these pitfalls:
- Treating p > 0.05 as “proof” of normality. It only means you cannot reject normality. The data may still deviate in ways that matter.
- Ignoring sample size effects. A statistically significant Shapiro-Wilk result with n = 5,000 may reflect a trivial real-world deviation.
- Relying on one method only. Numerical tests can be over- or undersensitive. Always pair them with visual inspection.
- Skipping group-level testing. Overall normality does not guarantee normality within subgroups.
- Forgetting to retest after transformation. A transformed variable must be retested to confirm the fix worked.
When Normality Testing Is Part of a Larger Workflow
In modern research operations, normality testing rarely happens in isolation. It sits inside a broader pipeline: data collection, cleaning, validation, analysis, reporting, and dashboarding. Each stage feeds the next, and a weak assumption check early on can compromise everything downstream.
For research teams running multiple concurrent projects across geographies and data sources, the challenge is scale. Manual assumption checks slow projects down. Automated, repeatable workflows – built around SPSS, R, Python, or integrated platforms – protect data quality without bottlenecking timelines.
This is where modern research infrastructure makes a difference. Standardised assumption testing, audit trails, real-time dashboards, and secure data handling turn statistical rigour from a friction point into a foundation for faster, more confident decisions.
Final Checklist Before Running Parametric Tests
Before moving on to your main analysis, confirm:
- You ran the Explore procedure with normality plots and tests enabled
- The Shapiro-Wilk p-value is above 0.05 (or sample-size-adjusted judgment applies)
- Skewness and kurtosis values fall within acceptable ranges
- The histogram and Q-Q plot visually support normality
- You tested normality within each group, where relevant
- You documented the test results and your interpretation
Once these are in place, you can confidently proceed with parametric analysis – and trust the insights that follow.
Closing Thought
Normality testing in SPSS is simple in execution but consequential in impact. Done well, it strengthens every statistical conclusion you draw. Done poorly, or skipped entirely, it undermines them.
For organisations where research drives strategy – market intelligence, customer insights, healthcare studies, social research – the difference between a defensible result and a questionable one often comes down to how well the early assumption checks were handled.
At Linkinfotech, we work alongside research teams to build scalable, technology-driven research operations where data quality, statistical rigour, and faster decision-making come standard. From survey programming to advanced analytics, our infrastructure ensures every analysis rests on a foundation you can trust.
If you would like to talk through how robust normality testing fits into your wider research operations. Get in touch.
